Dickimaw Books Blog 
Binary Files, Text Files and File Encodings 🔗
The TeX distribution comes with a mixture of binary files and text files. The source code for your document is written in a text file and you need a text editor to create and modify it, but you need to make sure the file (or input) encoding is correct otherwise you can end up with error messages, warnings and strange characters in your PDF file. This can be very confusing to new users without a computer science background who might ask, “what’s the difference between a binary file and a text file, and what does file encoding mean?” It can also confuse people with a computer science background who might blithely inform you that, naturally, a binary file is a file that has binary content and a text file is a file that contains plain text.
So what actually is the difference between a binary file and a text file, and what causes weird symbols to appear and “missing character” warnings?
This isn’t intended to be a lecture on hardware, so I’m going to simplify things somewhat, but digital devices (such as laptops, tablets and smartphones) essentially treat everything as binary data. Binary in this context means one of two states, so you can view the internals of a computer as a series of tiny switches that can either be on or off.

We could call these two states “on”/“off” or “up”/“down” or “true”/“false” but the most compact form for a human to visualise the two states of a tiny electronic switch is to use the digits 1 (on or up or true) and 0 (off or down or false).
Each switch is one bit and a sequence of eight bits is one octet. With 8-bit systems, eight bits is also one byte. (Half a byte, or four bits, is a nybble, but that’s not often used.) Your hard drive (or USB stick etc) is essentially full of bits. The device’s filing system contains an index of where each file starts and ends.

If you delete a file the index is removed but the bits remain.

So each file contains a sequence of bits and the file size is measured in bytes. In other words, all files have binary content.
The file format determines how the binary content should be interpreted. The format is basically a set of rules. If a file is identified as having a particular format but its content doesn’t follow the rules for that format, then the declared format is incorrect or invalid (which is what triggers an “invalid format” error if you try to open it).
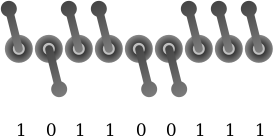
Suppose I have an application (called, say, FooBar) that allows me to draw either a rectangle or an ellipse. It’s very restrictive and only has a limited set of options: vertical/horizontal (is the shape’s long axis vertical? true/false), large/small (is the shape large? true/false), filled/open (is the shape filled? true/false), ellipse/rectangle (is the shape elliptical? true/false). Each setting is binary so the options can be compactly written as a series of bits. For example: vertical, small, open, ellipse can be written as 1001. This needs to be zero-padded to make it up to 8 bits (since most digital storage measurements are in bytes): 00001001.
Binary data is difficult for humans to read and write. The longer the sequence of bits, the harder it becomes, so programmers usually convert the value to hexadecimal (base 16) to make it more compact and easier to read. Each nybble (4 bits) can be represented by one hexadecimal digit (0–9, A–F) so one byte (8 bits) can be represented by two hexadecimal digits. Instead of writing 00001001, I can write the equivalent hexadecimal value: 09. (In order to clarify that the value is a hexadecimal not a decimal representation, it’s often prefixed with “0x”: 0x09. In this case, because the number is less than ten, it happens to be the same as decimal 9.)
Let’s now suppose that FooBar allows me to specify a colour for the shape as a combination of red, green and blue (RGB). Each of these three colours have a numerical value indicating how much of that colour to add where 0 indicates none of the colour and the maximum value indicates all of that colour. There are different scales for quantifying a colour, such as a decimal number between 0.0 and 1.0 or a percentage between 0% and 100% or an integer between 0 (0x00) and 255 (0xFF). The last scale is convenient for FooBar because it means that each of the three colour components can be stored in a single byte so the complete colour specification takes up three bytes.
I’d like my vertical, small, open, ellipse to be drawn in a sort of greyish-blue colour. After playing around with the colour selector I’ve found the shade I like: 0x42 (red), 0x6F (green) and 0x6F (blue).

Having created my work of art, I need to go off and do something else, but I’d like to save my ellipse so I can look at it again later. The most compact way of saving the information is in four bytes (the settings, followed by the red, green and blue values): 00001001 01000010 01101111 01101111. I’ve put a space between each group of eight bits here for clarity, but from the computer’s point of view this is just a sequence of 32 bits. From a human point of view the information looks better in hexadecimal: 09 42 6F 6F.
I need to think of a file name but I’m not very good at naming schemes so I’m just going to call it “image1”. The format is FooBar’s native binary format. The rules for this format are: the file must contain exactly four bytes, the first byte has the settings information stored in the last (least significant) four bits, the second byte is the amount of red, the third byte is the amount of green and the fourth byte is the amount of blue.
If I try to open a file in FooBar that only contains, say, three bytes, then this breaks the rules, so FooBar will popup an “invalid format” error message. What happens if the file has four bytes but the first four bits aren’t 0? Should they simply be ignored or should this trigger an invalid format error? The rules don’t say so the file format has an ambiguity in it.
An application can only read a file if it has been provided with the rules for the file format.
So if the content of all files is just a sequence of bits, what is a text file? A text file is simply a file that obeys one of the known text file formats or encoding. The most well known text encoding is the American Standard Code for Information Interchange (US-ASCII or, more colloquially, ASCII). The ASCII rules are: each byte must be in the range 0x0 to 0x7F (00000000 to 01111111, note that the most significant bit is always 0) and each byte either represents a control character (an instruction) or a printable character (letter, digit or punctuation). The ASCII table describes what each of the 128 allowed bytes represent.
For example, the byte 0x0A (00001010) is the line feed instruction. This means that whatever application is trying to interpret the data must move down one line. However, there is some ambiguity here as some systems will also move back to the first column (the start of the line) when encountering this line feed instruction but others require a carriage return instruction (0x0D) as well. (For those of you who remember using a typewriter, when you reached the end of a line, you had to hit a lever, which rotated the barrel one line, and also push the carriage across, which brought you back to the start of the line. Both actions were performed simultaneously with a single sweep of the hand. The line feed and carriage return terminology have carried over to the digital world.)
Another control code is 0x09 (00001001) which is the horizontal tab instruction. This means to move to the next tab stop, but it’s up to the application reading the data to define the tab stops. The space character (0x20) can also be considered a control code as it’s an instruction to move on one “space” without actually displaying anything.
The bytes in the range 0x21 to 0x7E are printable characters. Each of these values (or codes) has an associated shape (or glyph) that needs to be displayed. This shape is obtained from the font table, but the ASCII format doesn’t provide any information about what font should be used. That’s again up to the application reading the data.
For example, the byte 0x42 (01000010) represents the upper case Latin B and the byte 0x6F (01101111) represents the lower case Latin o. So if I create a file in a text editor that contains a tab followed by the word “Boo” and save it (as ASCII) then the file will contain four bytes: 00001001 01000010 01101111 01101111 (or 09 42 6F 6F).
These four bytes may look familiar. They are the same four bytes that make up the earlier “image1” file. So this file is both a FooBar binary file and an ASCII text file. It obeys the rules of both formats.
What happens if I replace the tab character with an upper case Latin I 0x49 (01001001)? This still obeys the ASCII format, but is it still a valid FooBar binary file? Remember that the FooBar format doesn’t say anything about the first four bits. If an application chooses to simply ignore the value of those first four bits then the file content will still be interpreted as a greyish-blue, vertical, small, open, ellipse.
Let’s suppose I increase the amount of blue and save the file so that it now contains the four bytes: 00001001 01000010 01101111 11111111 (or 09 42 6F FF). This is a valid FooBar binary file but it’s no longer valid ASCII as ASCII doesn’t allow a 1 in the first (most significant) bit of any of the 8-bit bytes.
ASCII only provides rules for 128 values (0x00 to 0x7F). This is quite a limited set of characters. It doesn’t include, for example, accented characters (such as é) or more aesthetic punctuation such as “smart quotes” or various length dashes — such as the em-dash. What if I want to add a pound sterling symbol (£)? The ASCII format doesn’t allow it, just as the FooBar format doesn’t allow a triangle. A different format is required.
The ISO-8859-1 encoding (or latin1) also has each character represented by an 8-bit byte but the range goes up to 0xFF (11111111). The first 128 values are identical to ASCII, but there are extra characters available (where the first — most significant — bit is 1) including the pound £ symbol (0xA3) and ÿ (0xFF). This means that my modified FooBar binary file with the extra blue (09 42 6F FF) is also a valid ISO-8859-1 text file. If I open the file in a text editor and stipulate the ISO-8859-1 encoding then it will interpret the contents as a tab followed by the characters “Boÿ”.
Although ISO-8859-1 provides some accented characters and some extra punctuation (such as guillemets « and ») there are still many characters that are unavailable. A more comprehensive format (text encoding) is UTF-8, which is a variable-width character encoding. This means that some characters are represented by more than one byte.
Just as ASCII is a subset of ISO-8859-1, ASCII is also a subset of UTF-8, which means that all the bytes from 0x00 to 0x7F in UTF-8 are identical to ASCII so, for example, 01101111 (6F) still represents a lower case Latin o. However, unlike ISO-8859-1, the non-ASCII characters are identified by two or more bytes in UTF-8. For example, the pound £ symbol requires two bytes: 11000010 10100011 (C2 A3).
Let’s suppose I now have a file containing the four bytes: 11000010 10100011 00110001 00110010 (C2 A3 31 32). If I open this in a text editor, identifying the text encoding as UTF-8, then the first two bytes will be interpreted as the single character £, the next byte is the digit 1 and the final byte is the digit 2, so I have three characters in total “£12” and the file is four bytes long. If I instead identify the text encoding as ISO-8859-1 then each byte is a separate character, where the first byte is the upper case Latin A with circumflex (Â), so I now have four characters in total “£12”.
Is this still a valid FooBar binary file? Yes, it is, provided we are adopting the lax approach of ignoring the first four bits.

Is this a valid ASCII file? No, because it contains bytes outside of the valid range.
Let’s go back to the original “image1” file and reduce the green to 0x08 and save the image as a file called, say, “testfile”. This contains the four bytes: 00001001 01000010 00001000 01101111 (09 42 08 6F). This is a FooBar binary file but is it also a text file? ASCII defines 00001000 (0x08) as the backspace control code, which is an instruction to move back one space. So this is also a valid ASCII file, but let’s see how it looks if we view it in a text editor. My preferred editor is vim:
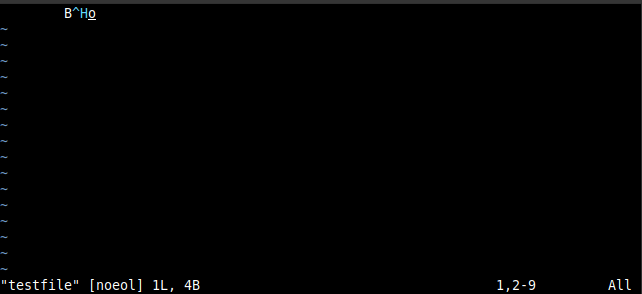
This shows a space eight characters wide (which is the result of the tab 0x09), the upper case letter B (0x42), but this is followed by a sequence in cyan consisting of ^H. It’s in cyan to highlight the fact that it’s not the two characters ^ and H but is a control code with the value 0x08 (H is the eighth letter of the alphabet). This is caret notation and is used to denote control codes. This is followed by the final character (lower case o).
Not all text editors use caret notation. Here’s how this file looks like in gedit:
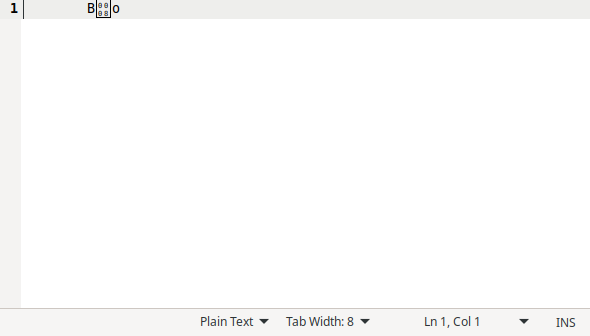
In this case the control code is shown using a rectangle with the control code’s hexadecimal value inside it (in this case padded to four digits 0008).
If, on the other hand, I display the file contents using cat in a bash terminal then the result is just a space eight characters wide followed by the lower case o. This is because cat obeys the control code instruction. It firsts moves the cursor to the next tab stop (which creates the initial space), then it prints the letter B, then it moves the cursor back one space, then it prints the letter o, which overwrites the B.
The purpose of a text editor is to create and edit files. If I type Tab Shift+B Backspace o in the text editor then it will interpret the backspace as an instruction to remove the previous character from the buffer. If I then save the file, it will only contain 00001001 01101111 (the tab character and the lower case Latin o). It won’t contain the unwanted B and the backspace character. Therefore, if I open a file in a text editor that contains a control code, such as backspace, the editor will assume that I want a visual representation of the character and won’t interpret it as an instruction.
Although this file is valid ASCII, it would normally be considered just a binary file not a text file because it looks weird if you open it in a text editor.
An application may be able to read a text file (that is, it knows the file format rules), but that doesn’t mean that it will follow the actions assigned to control codes (such as backspace), and there is no guarantee that the font the application is using has an associated glyph for a particular printable character.
UTF-8 also has control characters, such as the zero width joiner, which consists of three bytes (0xE2 0x80 0x8D), and the “variation selector-16” character, which also consists of three bytes (0xEF 0xB8 0x8F). These are used to apply attributes to emoji. For example, the superhero character 🦸 consists of four bytes (0xF0 0x9F 0xA6 0xB8) and the female sign ♀ consists of three bytes (0xE2 0x99 0x80). The sequence of thirteen bytes 0xF0 0x9F 0xA6 0xB8 0xE2 0x80 0x8D 0xE2 0x99 0x80 0xEF 0xB8 0x8F (superhero, zero width joiner, female sign, variation selector-16) identifies the female superhero emoji 🦸♀️. However, some applications may not have the function required to implement this and may end up displaying the superhero and female symbols: 🦸♀ (if the font being used has a corresponding glyph for those characters).
If the font doesn’t have a glyph for a particular character then a “not defined character” glyph may be used instead. This could be a rectangle with the hexadecimal value inside (as with the gedit example above) or it could simply be an open rectangle ▯ or a rectangle containing a question mark. (If a byte is invalid — that is, it’s not valid for the given text format — then the replacement character � is typically used.)
So, just because a file has a valid text format, it doesn’t necessarily mean that an application that is ordinarily able to read text files won’t encounter some difficulty with certain characters in that file.
What happens if I try to input my original “image1” file into a LaTeX document:
\documentclass{article}
\begin{document}
\input{image1}
\end{document}
The \input{} command expects the file identified in the braces to be a LaTeX file. This means that it expects the file to be a text file that contains LaTeX markup. So the contents of “image1” won’t be interpreted as a FooBar image but will be interpreted as the characters Tab B o o. LaTeX doesn’t interpret the Tab control code as a tabulation instruction but instead treats it as a space. It also ignores any spaces at the start of a line (which allows you to indent your source code to make it easier to read without introducing spurious spaces). The result is a PDF file with the word “Boo”.
Now let’s replace \input{image1} with \input{testfile} (the file shown in vim and gedit above) and try compiling (building) the document with pdflatex. This triggers the following error:
! Package inputenc Error: Unicode character ^^H (U+0008)
(inputenc) not set up for use with LaTeX.
See the inputenc package documentation for explanation.
Type H <return> for immediate help.
...
l.1 B^^H
o
?
This is complaining about the third byte in “testfile”, which LaTeX is interpreting as the Unicode character U+0008 (the backspace character). LaTeX has no instructions regarding this character as it’s not a character that would ordinarily be found in LaTeX source code. LaTeX knows what this character is (U+0008), but it doesn’t know what to do with it. If I type h Return at the prompt (the question mark at the bottom) then I get the following message:
You may provide a definition with \DeclareUnicodeCharacter
This is telling me that if I want to use this character then I need to declare it and provide instructions as to how LaTeX should deal with it. If I press Return at this point and let LaTeX carry on processing then it will ignore the backspace character, so the resulting PDF will simply display “Bo”.
In neither of the above cases do I get a PDF with an image of a small ellipse because \input expects the file to contain (La)TeX instructions and will parse it as such.
You may have noticed that the error message above mentions the inputenc package even though the document hasn’t loaded it. In that example, I was using the TeX Live 2021 distribution. If I use an older distribution, say, TeX Live 2016 then I get a different error message and a different help message:
l.1 B^^H
o
? h
A funny symbol that I can't read has just been input.
Continue, and I'll forget that it ever happened.
?
In both cases the backspace character is ignored and the result is the same.
Now let’s try the four-byte file that can be interpreted as the UTF-8 characters “£12”: 11000010 10100011 00110001 00110010 (C2 A3 31 32). With pdflatex from TeX Live 2016, there’s no error message but the log file contains the following warnings:
Missing character: There is no  in font cmr10! Missing character: There is no £ in font cmr10!
So this is interpreting the first two bytes of the file as two separate characters, Â (0xC2) and £ (0xA3), but there’s no glyph available for either of these characters in the default font (cmr10). So the PDF just contains “12”. With TeX Live 2021, there are no errors or warnings and the PDF contains “£12”.
Donald Knuth first released TeX in 1978, and Leslie Lamport released LaTeX in 1985. ISO-8859-1 was also first published in 1985, but UTF-8 was designed in 1992. (ASCII was first published in 1963.) So it’s not surprising that the original versions of TeX and LaTeX were designed for single byte text encodings.
The great advantage about UTF-8 is that it covers all Unicode characters (as opposed to ISO-8859-1, which is limited to 256 characters, and ASCII, which is limited to 128 characters). It’s natural that users who wanted to be able to type extended Latin or non-Latin characters into their LaTeX document source code were keen to adopt UTF-8. This is awkward for (La)TeX, which treats each byte as a separate token. The inputenc package (with the utf8 setting) provides a workaround: it makes the first byte of a multi-byte sequence an active character which takes the subsequent byte as its argument. This can be demonstrated by the following UTF-8 document:
\documentclass{article}
\usepackage[utf8]{inputenc}
\begin{document}
\show £
\end{document}
This produces the following message in the transcript:
> �=macro:
->\UTFviii@two@octets �.
l.4 \show �
�
The \show command displays the definition of the token that follows it. In this case, the command is followed by two tokens: the two bytes (0xC2 and 0xA3) that indicate the £ symbol. So \show picks up the first token (0xC2) and shows the definition. This token (0xC2) is written to the transcript, but the transcript is being viewed in a bash terminal that’s expecting UTF-8 content. The 0xC2 byte isn’t followed by a legitimate byte (as defined by the UTF-8 format) so it’s flagged with the replacement symbol � to denote that it’s invalid. If I view the transcript in vim with the binary mode on, I can see the value of the bytes.

This shows that the 0xC2 byte (octet) has been defined as a macro (command) that expands to \UTFviii@two@octets followed by the byte 0xC2. This internal command is defined to take two arguments: the first is provided (0xC2, the first byte in the two-byte pair) and the second is the token that follows (the second byte in the two-byte pair).
If I press Return to continue processing the document I encounter an error because the second byte (0xA3) of the two-byte pair has become detached. The transcript in the bash terminal at this point is:
! Package inputenc Error: Invalid UTF-8 byte "A3.
See the inputenc package documentation for explanation.
Type H <return> for immediate help.
...
l.4 \show £
If I look at the log file in vim again, but this time without the binary mode on, then vim determines that the file can’t be a UTF-8 file (because it breaks the UTF-8 rules) so it decides that it must be an ISO-8859-1 file:
> Â=macro:
->\UTFviii@two@octets Â.
l.4 \show Â
£
?
! Package inputenc Error: Invalid UTF-8 byte "A3.
See the inputenc package documentation for explanation.
Type H <return> for immediate help.
...
l.4 \show £
Recent changes to the LaTeX kernel in the past few years mean that UTF-8 is now the default encoding for LaTeX document source files, but this trick is still employed. If you want the multi-byte UTF-8 characters to be treated as a single token then you need to switch to a modern TeX engine (XeLaTeX or LuaLaTeX), which natively supports UTF-8.
So how do you tell what format (or encoding) a file is in? That is unfortunately quite difficult. You can parse the file and find out if it breaks a rule (is invalid) to determine if it’s not a particular format. For example, if the file contains a byte larger than 0x7F then it’s definitely not ASCII, or if the file contains a byte such as 0xC2 that isn’t followed by a byte (or bytes) that results in a valid UTF-8 character then the file isn’t UTF-8. However, as illustrated by the “image1” file, just because the file contents satisfy the rules of one format doesn’t mean that it doesn’t also coincidentally satisfy the rules of another format.
One general rule of thumb is that if the file contains a certain proportion of bytes that represent control characters (such as the earlier backspace example) then it’s likely to be a binary file. However, just because a file only contains bytes that represent printable characters doesn’t mean that the file isn’t a binary file.
Some formats use a “magic marker”: a sequence of bytes at the start of the file that identifies the format. For example, a PDF 1.3 file will start with the bytes 0x25 0x50 0x44 0x46 0x2D 0x31 0x2E 0x33 (which represents the ASCII characters “%PDF-1.3”). However, there’s nothing to stop me from starting a LaTeX file with the lines:
%PDF-1.3 \pdfmajorversion=1 \pdfminorversion=3
In this case, the first line is a comment to remind the author (or anyone else reading the source code) that the next two lines are stipulating that the resulting PDF file must be version 1.3, but this is enough to confuse some applications into thinking that this LaTeX source file is a PDF file.
The byte order mark (BOM) is another form of magic marker that’s used to indicate the byte-endianness of a UTF-16 or UTF-32 file. For example, a big endian byte order UTF-16 file will start with the bytes 0xFE 0xFF. UTF-8, on the other hand, only has one byte order so, although the BOM character is defined in UTF-8, there’s no point in using it to indicate the byte order.
Despite this, the BOM character is sometimes used at the start of a file to simply indicate that the file is UTF-8, but this can be problematic. If a text editor automatically inserts it at the start of every file that it saves, then it forces the file to be UTF-8 even if there are no non-ASCII characters in the content. This makes it less compatible with other applications, particularly when the file is a script for a language that has it’s own magic marker (such as bash file that must start with #!).
Another way of indicating the file format is to incorporate the information in the file name. This is typically done in the form of a suffix that starts with a dot (the file extension). For example, “image.jpg” indicates a JPEG file and “image.png” indicates a PNG file. There can be multiple extensions. For example, the file “myDoc.synctex.gz” has the extension “.gz” which means that it uses the gzip compression format. If I uncompress it (gunzip myDoc.synctex.gz) then I will have the file “myDoc.synctex”, which is in the synctex format.
Some filing systems hide the extension when showing the list of files. This can be particularly annoying for LaTeX users because a directory (folder) can become full of files with the same basename but different extensions. For example, if I create a document called, say, “myDoc.tex” then using pdflatex will, at the very least, create the files “myDoc.log”, “myDoc.aux” and “myDoc.pdf”. Once a table of contents, list of figures, list of tables, bibliography, index, glossaries etc are added, the file list increases significantly and it can be hard to tell which is which if the extensions are hidden.
More generally, hiding the file extensions can have serious security implications. An executable file called, say, “notes.txt.exe” will be displayed as “notes.txt” which gives the impression that it’s just a text file, but if you double-click on it, expecting to open it in a text editor, the file will instead be executed. This is one way in which users can be tricked into running a malicious executable file.
Unfortunately there’s nothing to stop anyone from renaming the file so that it has a different extension. For example, if I rename a PNG file from “image.png” to “image.jpg” then this doesn’t alter the file content — it’s still a PNG file — but it misrepresents the file, making it look like a JPEG file when it’s actually a PNG file. This can confuse an application that tries to determine the file type from the file name extension, and it will try to read the file using the wrong set of rules.
Another way of identifying the file format is with the MIME type but, as with file extensions, the MIME type can be incorrect (either through accident or deliberately).
Returning to my FooBar “image1” file (which doesn’t have an extension), if I forget about it and stumble on it months later, the chances are that I will have forgotten what it was and what I used to create it. My first step will be to try to identify it with the file tool. This returns “image1: ASCII text, with no line terminators” so my next step will be to open it in a text editor, where I will find the message: Tab Boo. Therefore the developer of the FooBar application really needs to modify the file format so that it includes a magic marker at the start and also decide on a file extension to help identify what type of file it is.
Can I include my FooBar ellipse in my LaTeX document? Not in its FooBar binary format. I would first need to convert it to a graphics format that \includegraphics recognises.
So in summary:
- All files contain binary data.
- The file format is the algorithm or set of rules needed to understand the data contained in the file.
- The term “text file” is used to indicate a file that is written in one of the standard text file formats (such as ASCII, ISO-5988-1 or UTF-8) that is intended to be readable in a text editor (that is, it doesn’t have a high proportion of non-whitespace control codes).
- The term “binary file” is used to indicate a file that is not a text file.
- The file (or input) encoding of a text file is the particular text format used to store the textual data in the file.
- An application can only properly parse or process a file if it recognises and understands the file’s format.
- If the format is mis-identified then this can either cause outright failure (“invalid format”) or incorrect instructions (such as placing an unwanted  before a £).
Next Post
Previous Post
 You’ve probably come across websites that want you to prove that you’re human and not a robot. This may come in the form of a picture challenge (for example, select all the squares with bicycles) or it may simply require you to check a box to assert that you’re not a robot. Perhaps you’re wondering why you need to do this. Why is the website so concerned about being visited by robots? Alternatively, perhaps you’re a website developer and are determined to find a way to keep out all bots.
You’ve probably come across websites that want you to prove that you’re human and not a robot. This may come in the form of a picture challenge (for example, select all the squares with bicycles) or it may simply require you to check a box to assert that you’re not a robot. Perhaps you’re wondering why you need to do this. Why is the website so concerned about being visited by robots? Alternatively, perhaps you’re a website developer and are determined to find a way to keep out all bots.Recent Posts
 Within FlowframTk, it’s possible to assign descriptions and tags to objects to make them easier to select and find in a complicated image. This post provides an example.
Within FlowframTk, it’s possible to assign descriptions and tags to objects to make them easier to select and find in a complicated image. This post provides an example. The evolution of a vector graphics application inspired by Acorn's !Draw application designed for integration with LaTeX documents, either exporting images as pgf code or exporting document classes or packages that use the flowfram package. The application was originally named JpgfDraw but was then renamed FlowframTk.
The evolution of a vector graphics application inspired by Acorn's !Draw application designed for integration with LaTeX documents, either exporting images as pgf code or exporting document classes or packages that use the flowfram package. The application was originally named JpgfDraw but was then renamed FlowframTk. There are a growing number of digital historians who are interested in documenting old computing systems from the twentieth century, but much of the information has been lost and coincident names can make it hard to search. This article is about the RISC OS ARMTeX distribution, which provided TeX and LaTeX for the ARM-powered Acorn computers in the 1990s.
There are a growing number of digital historians who are interested in documenting old computing systems from the twentieth century, but much of the information has been lost and coincident names can make it hard to search. This article is about the RISC OS ARMTeX distribution, which provided TeX and LaTeX for the ARM-powered Acorn computers in the 1990s. The DRM-free ebook retailer SmashWords has its annual Summer/Winter sale from 1st – 31st July 2025. My crime novel “The Private Enemy” and children’s illustrated story “The Foolish Hedgehog” both have a 50% discount, and my crime fiction short stories “I’ve Heard the Mermaid Sing”, “Unsocial Media”, “Smile for the Camera”, and “The Briefcase” have a 100% discount (i.e. free!) for the duration of the sale. Did you know that you can gift ebooks on SmashWords?
The DRM-free ebook retailer SmashWords has its annual Summer/Winter sale from 1st – 31st July 2025. My crime novel “The Private Enemy” and children’s illustrated story “The Foolish Hedgehog” both have a 50% discount, and my crime fiction short stories “I’ve Heard the Mermaid Sing”, “Unsocial Media”, “Smile for the Camera”, and “The Briefcase” have a 100% discount (i.e. free!) for the duration of the sale. Did you know that you can gift ebooks on SmashWords? If you have read my short story Smile for the Camera, did you notice that the ending could have two possible interpretations? (No spoilers please!) As a writer, it’s always difficult to tell if something is too obvious or too obscure. If you need a hint, consider the naming scheme and remember that not everyone is what they say or imply that they are.
If you have read my short story Smile for the Camera, did you notice that the ending could have two possible interpretations? (No spoilers please!) As a writer, it’s always difficult to tell if something is too obvious or too obscure. If you need a hint, consider the naming scheme and remember that not everyone is what they say or imply that they are.Search Blog
📂 Categories
- Autism
- Books
- Children’s Illustrated Fiction
- Illustrated fiction for young children: The Foolish Hedgehog and Quack, Quack, Quack. Give My Hat Back!
- Creative Writing
- The art of writing fiction, inspiration and themes.
- Crime Fiction
- The crime fiction category covers the crime novels The Private Enemy and The Fourth Protectorate and also the crime short stories I’ve Heard the Mermaid Sing and I’ve Heard the Mermaid Sing.
- Fiction
- Fiction books and other stories.
- Language
- Natural languages including regional dialects.
- (La)TeX
- The TeX typesetting system in general or the LaTeX format in particular.
- Music
- Norfolk
- This category is about the county of Norfolk in East Anglia (the eastern bulgy bit of England). It’s where The Private Enemy is set and is also where the author lives.
- RISC OS
- An operating system created by Acorn Computers in the late 1980s and 1990s.
- Security
- Site
- Information about the Dickimaw Books site.
- Software
- Open source software written by Nicola Talbot, which usually has some connection to (La)TeX.
- Speculative Fiction
- The speculative fiction category includes the novel The Private Enemy (set in the future), the alternative history novel The Fourth Protectorate, and the fantasy novel Muirgealia.
🔖 Tags
- Account
- Alternative History
- Sub-genre of speculative fiction, alternative history is “what if?” fiction.
- book samples
- Bots
- Conservation of Detail
- A part of the creative writing process, conservation of detail essentially means that only significant information should be added to a work of fiction.
- Cookies
- Information about the site cookies.
- Dialect
- Regional dialects, in particular the Norfolk dialect.
- Docker
- Education
- The education system.
- Ex-Cathedra
- A Norfolk-based writing group.
- Fantasy
- Sub-genre of speculative fiction involving magical elements.
- File formats
- FlowframTk
- A vector graphics application written in Java that can export to pgf picture drawing code but can also be used to construct frames for use with the flowfram package. Home page: dickimaw-books.com/software/flowframtk. (FlowframTk was originally called JpgfDraw.)
- Hippochette
- A pochette (pocket violin) with a hippo headpiece.
- History
- I’ve Heard the Mermaid Sing
- A crime fiction short story (available as an ebook) set in the late 1920s on the RMS Aquitania. See the story’s main page for further details.
- Inspirations
- The little things that inspired the author’s stories.
- Linux
- Migration
- Posts about the website migration.
- Muirgealia
- A fantasy novel. See the book’s main page for further details.
- News
- Notifications
- Online Store
- Posts about the Dickimaw Books store.
- Quack, Quack, Quack. Give My Hat Back!
- Information about the illustrated children’s book. See the book’s main page for further details.
- Re-published
- Articles that were previously published elsewhere and reproduced on this blog in order to collect them all together in one place.
- Sale
- Posts about sales that are running or are pending at the time of the post.
- Site settings
- Information about the site settings.
- Smile for the Camera
- A cybercrime short story about CCTV operator monitoring a store’s self-service tills who sees too much information.
- Story creation
- The process of creating stories.
- TeX Live
- The Briefcase
- A crime fiction short story (available as an ebook). See the story’s main page for further details.
- The Foolish Hedgehog
- Information about the illustrated children’s book. See the book’s main page for further details.
- The Fourth Protectorate
- Alternative history novel set in 1980s/90s London. See the book’s main page for further details.
- The Private Enemy
- A crime/speculative fiction novel set in a future Norfolk run by gangsters. See the book’s main page for further details.
- Unsocial Media
- A cybercrime fiction short story (available as an ebook). See the story’s main page for further details.
- World Book Day
- World Book Day (UK and Ireland) is an annual charity event held in the United Kingdom and the Republic of Ireland on the first Thursday in March. It’s a local version of the global UNESCO World Book Day.
- World Homeless Day
- World Homeless Day is marked every year on 10 October to draw attention to the needs of people experiencing homelessness.